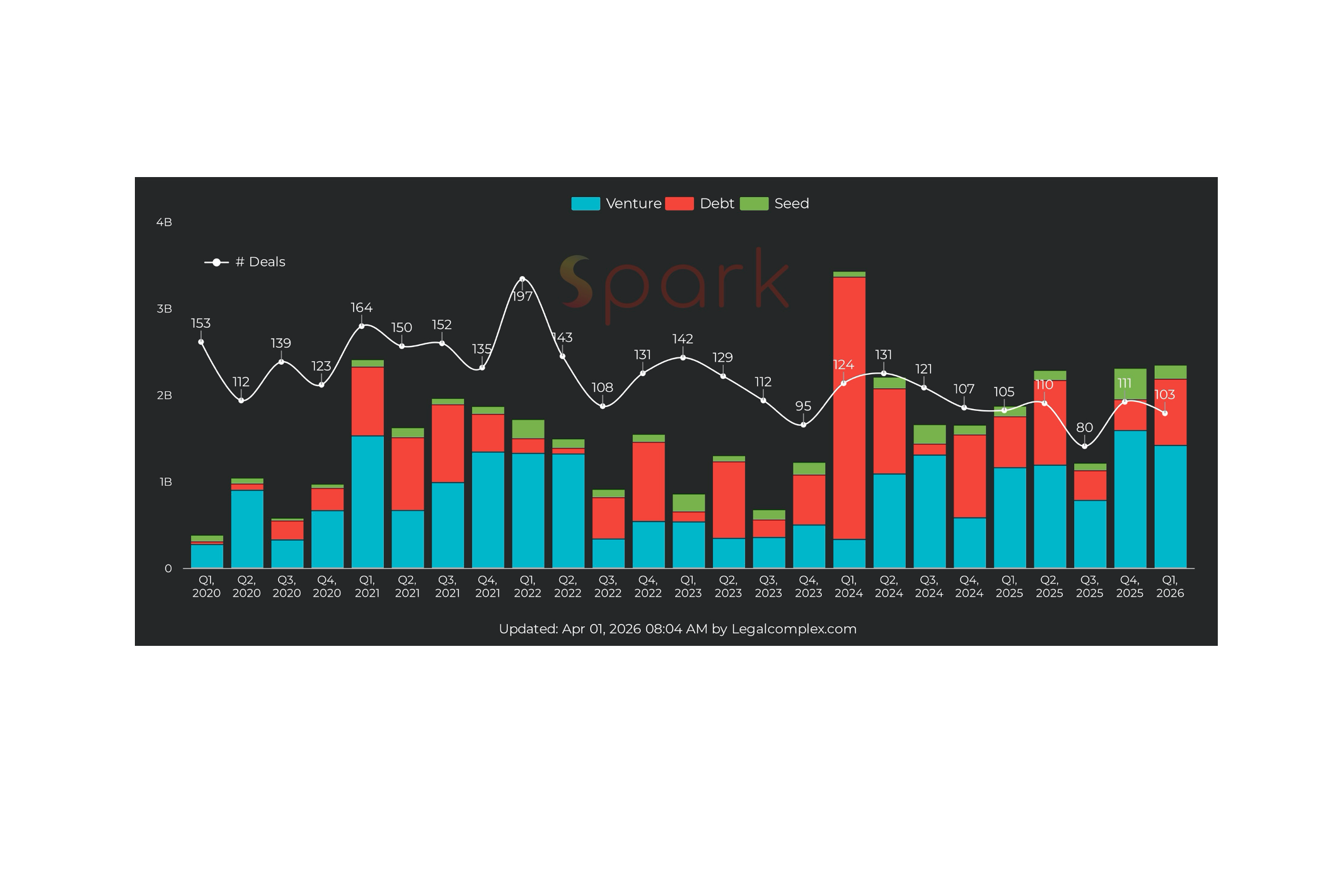
AI時代に「忘れられる権利」は機能するのか? データ削除の難問
AIシステムが個人データから学習することで、真のデータ削除が技術的・概念的に困難になり、「忘れられる権利」はかつてない試練に直面している。
⚡ Key Takeaways
- モデル学習による削除の複雑化 — データベースレコードとは異なり、AIトレーニングに使用された個人データは、学習されたパターンを通じてモデルパラメータに埋め込まれ、従来の削除アプローチでは不十分となる。 𝕏
- アルゴリズム収益剥奪が先例となる — FTCは、不正に取得されたデータでトレーニングされたモデルの削除を企業に要求し、トレーニングデータの出所の重要性と、モデルが破棄命令の対象となりうることを示した。 𝕏
- 機械アンラーニングはまだ成熟途上 — 正確なアンラーニングと近似アンラーニングの手法は開発中だが、計算コスト、有効性の保証、検証の課題といったトレードオフがあり、実運用展開を制限している。 𝕏

Worth sharing?
Get the best Legal Tech stories of the week in your inbox — no noise, no spam.