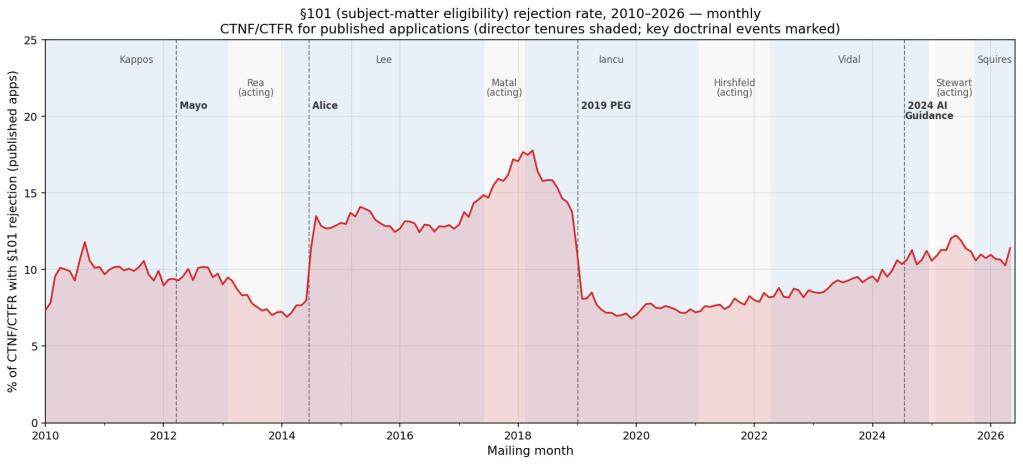
The digital hum of the USPTO’s vast data archives, a seemingly unassailable bedrock of patent law analysis, just experienced a seismic tremor.
For years, the prevailing narrative around Section 101 patent eligibility rejections—that they’ve been steadily trending downwards, perhaps in response to evolving judicial doctrine—has been subtly, but crucially, misinformed. Dennis Crouch, the meticulous data sleuth behind Patently-O, pulled back the curtain this week, revealing that a significant data anomaly had skewed our understanding of examiner behavior for sixteen years.
It’s not just a minor tweak; it’s a recalibration. Three weeks ago, Crouch dropped a deep dive into millions of office actions, arguing that USPTO administrative policy, not Supreme Court case law, was the real driver of examiner decisions on eligibility. The initial analysis, based on data pulled through early 2026, suggested a pattern. But then came the discovery: errors in the data pipeline. Specifically, the optical-character-recognition (OCR) process silently failed on longer office actions, and a substantial chunk of USPTO rejections had simply vanished from the bulk dataset, necessitating a painstaking reconstruction via API calls.
The Ghost in the Machine: What Was Missing?
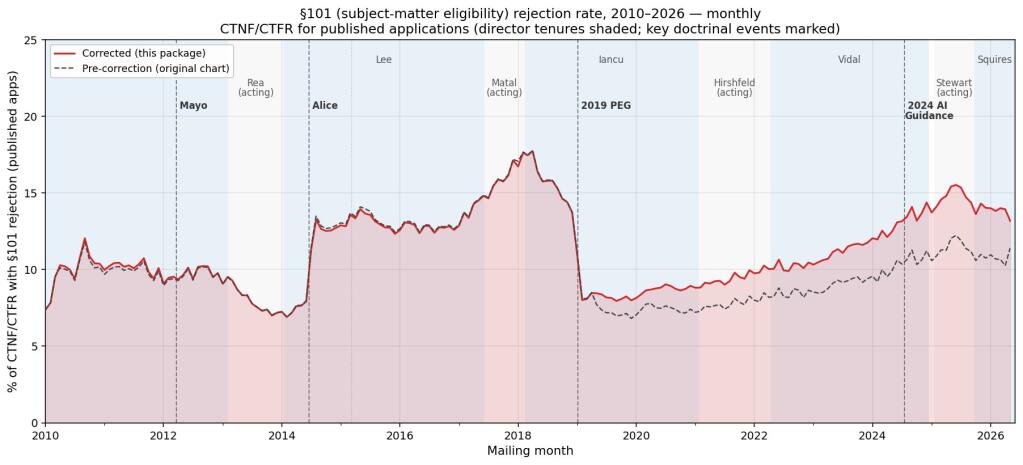
This isn’t just about a few lost lines of code or a misplaced comma. We’re talking about a systematic undercount of rejections. The original chart, a dashed line on Crouch’s analysis, showed a near-identical trend to the corrected, solid line through early 2019. Then, the paths diverged, growing wider and wider as data from 2019 through 2025 was re-examined. The corrected data paints a more dramatic picture: the post-2019 recovery in rejection rates is substantially larger than initially understood. This pushes the rate back up to around 15.5% by mid-2025, nearing the pre-PEG (Patent Examination Guidelines) peak—a period often characterized by much stricter eligibility standards.
And the recent decline? The one attributed to the tenures of Stewart and Squires? It’s also larger than first thought, though still dwarfed by the post-2019 surge. This correction doesn’t fundamentally dismantle Crouch’s central thesis—that examiner behavior tracks administrative policy more than judicial doctrine—but it amplifies it. It suggests that the USPTO’s internal directives and examiner training likely exerted a more consistent and impactful influence than previously quantifiable.
Why This Matters: Beyond the Numbers
For anyone tracking patent eligibility, this is more than an academic footnote. It’s a vital data correction that impacts how we interpret the effectiveness of everything from USPTO guidance memos to judicial pronouncements. If examiner behavior has been more closely tethered to internal policy all along, then shifts in policy are the real levers, not necessarily the nuanced pronouncements from the bench that lawyers and patent professionals pore over.
Think about it: the legal tech tools and analytics platforms that lawyers and businesses rely on to gauge patentability and predict outcomes? Many of them were likely operating with this slightly-off calibration. This forces a reassessment of the confidence intervals surrounding those predictions. A 15.5% rejection rate, up from a previously estimated lower figure, represents a tangible increase in risk for innovators seeking patent protection, particularly in software and business method patents—areas historically fraught with §101 challenges.
My own take here is that this incident is a stark reminder of the inherent fragility of large-scale data analysis, even within government institutions. We’ve become accustomed to the idea of data as objective truth, especially when it’s coming from an official source like the USPTO. But the reality is, data is constructed, processed, and inherently prone to the limitations of the tools and methodologies used. The OCR failure, a seemingly simple technical hiccup, cascaded into a misrepresentation of a critical legal and economic trend.
A Historical Parallel: The Illusion of Progress
It’s reminiscent, in a way, of early economic forecasts that relied on incomplete data sets, leading to policies that didn’t quite hit their mark. The illusion of progress, of a steady march towards a more predictable patent landscape, might have masked a more cyclical or policy-driven reality. This correction suggests that the ‘progress’ was, for a significant period, an artifact of the data itself, not necessarily a reflection of a fundamental shift in how eligibility is applied on the ground.
This isn’t to say the Supreme Court hasn’t had any influence; it clearly has. But the degree and nature of that influence, particularly on the day-to-day decisions of examiners, might have been overstated. Crouch’s original argument, now bolstered by this corrected dataset, places more emphasis on the internal gears of the USPTO – the training, the guidelines, the administrative pressures – as the primary shapers of examiner behavior. This provides a clearer roadmap for practitioners and policymakers looking to influence patent eligibility outcomes: focus on the administrative mechanisms within the USPTO, not just the judicial pronouncements.
The corrected chart does not disturb the central thesis, but it does provide additional insight. The two are nearly identical through early 2019 but then diverge afterward, with the gap widening through 2024 and 2025.
This isn’t the end of the story, of course. It’s the beginning of a re-examination. As more refined data tools emerge and data integrity checks become even more sophisticated, we can hope for increasingly accurate pictures of how our legal and technological landscapes are truly evolving. For now, though, the USPTO’s §101 journey looks a bit different—and perhaps more revealing—than we thought.
🧬 Related Insights
- Read more: Can AI Build Itself? $650M Bet on Self-Improving Code
- Read more: Harvey’s Contract AI for Inhouse: Beyond the Hype
Frequently Asked Questions
What does Section 101 in US patent law refer to? Section 101 defines what is patentable subject matter, including processes, machines, manufactures, and compositions of matter, but famously excludes abstract ideas, laws of nature, and natural phenomena.
Will this data correction impact my pending patent application? It’s unlikely to directly alter the legal standing of a pending application, but it may inform patent prosecution strategies and appeals based on a more accurate understanding of historical rejection rates and examiner tendencies.
How does OCR technology work in this context? OCR (Optical Character Recognition) converts images of text (like scanned documents or PDFs of office actions) into machine-readable text, enabling analysis. Errors can occur due to poor scan quality, complex formatting, or insufficient training data for the specific document type.